UnrealEngine Niagaraを使ったパーティクルシステムについて
公式のチュートリアルをやってる
Niagara のクイック スタート ガイド | Unreal Engine ドキュメント
雲っぽいメッシュをblenderで作ったんだけど、明らかに大きすぎるのでパーティクルでの発生時に小さくしたい。
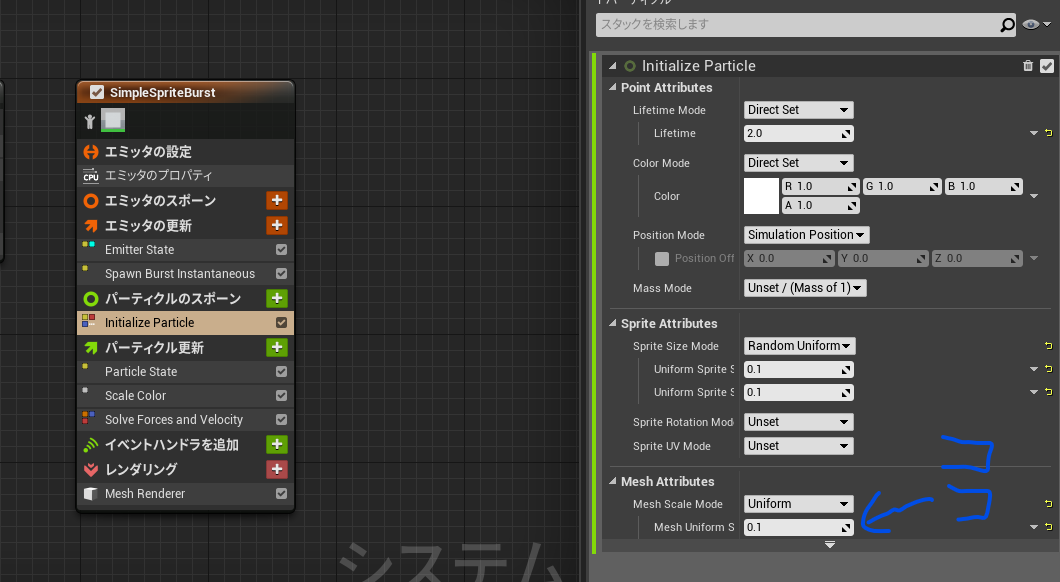
ここでやった。小さくはなったけどやりかた合ってるんかな。
カスケード(?)のパーティクル作った時はXYZの座標で縮小比設定できたから、ひとつの値で一律で変更しちゃってるの正しいのかな...ってなってる。
大釜を混ぜる
釜を混ぜる以上、液体をゲーム内で表現しなくちゃいけない。とりあえずオリジナルで作ってみる。
とりあえずこういう方法を考えた。

当たり判定のある球体と、それを包む大きめの当たり判定の無い球体を水粒子にみたててつくってみる。
これをすることで
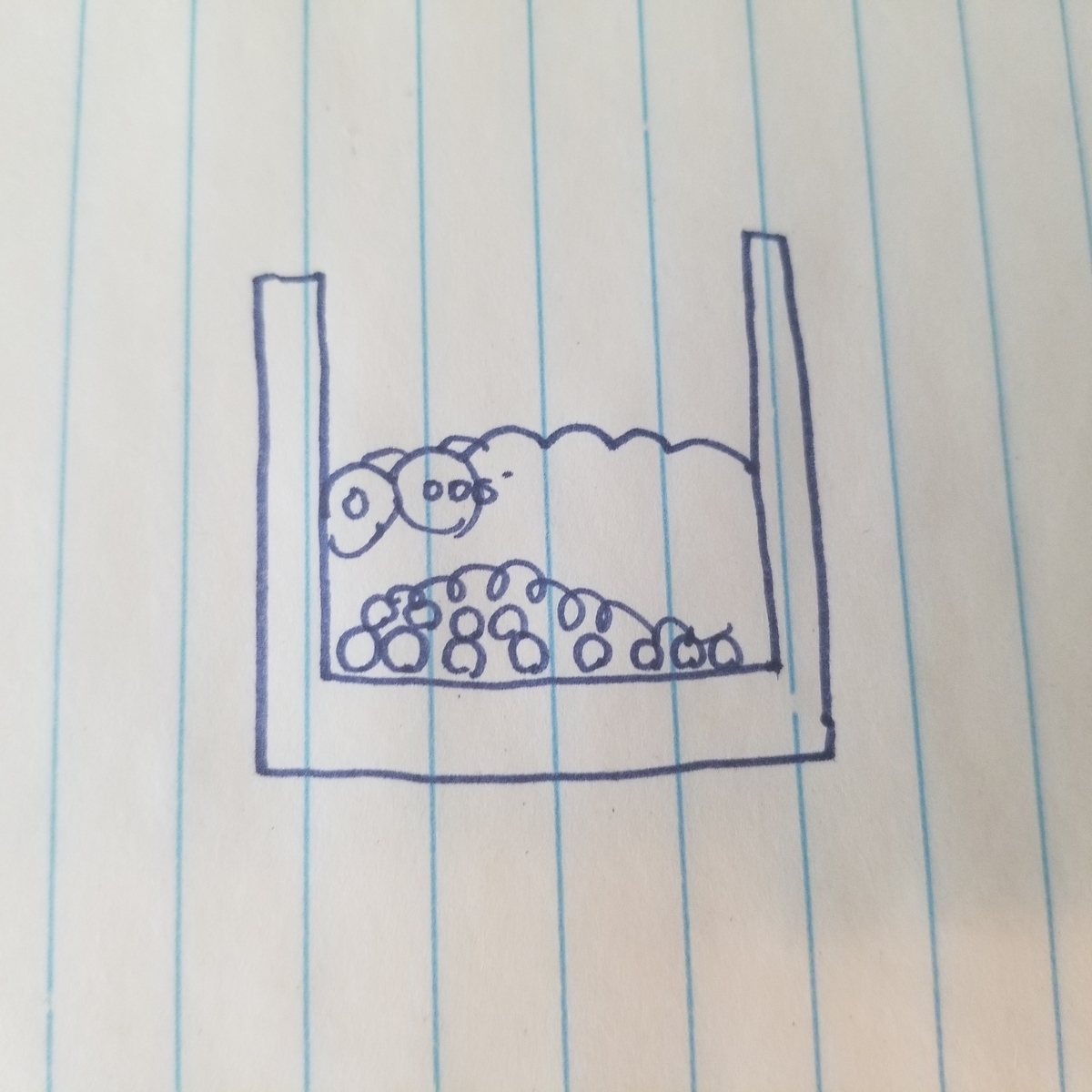
うまい具合にお互いが干渉しあって、プレイヤー視点からは当たり判定の無い外殻の部分が表示されて水っぽくみえるんじゃないかって算段。
やってみた
液体表現テスト pic.twitter.com/lxOsFoFT5f
— イイノテン (@iinoten) 2021年3月2日
良い感じじゃない?
もっとわかりやすく、外部分の球を半透明にしたやつ。
液体の表現テスト2 pic.twitter.com/YjubZZuJYP
— イイノテン (@iinoten) 2021年3月2日

さすがにちょっとボールボールしてるし、鍋からなんかはみでてる。でも良い感じだし球をもっと小さくしてもっと配置してみれば!!!!
液体表現テスト3 (処理が重すぎてカクカク) pic.twitter.com/H5ntMV3cbS
— イイノテン (@iinoten) 2021年3月2日
物理エンジン的に、大量の球がぶつかりあい、なおかつかきまぜられる処理はキツかったみたい。 パソコンがブンブン言いだした。鍋の底を覗くと視界が固まる。魔法使いの鍋なんだしそれはそれでいいのか。でもゲームとしてはダメかな。
ちょっとやりかた考えないといけない
VRゲーム開発のイメージをつくる
なんにせよ何かを開発する時や作る時って「なにを作るか」を明確にしておくのが重要だなってこれまでに学んできてるから、それからしようと思う。要件定義ってほど厳密なのはまだやらなくて、とりあえずのイメージ
目的
・VRでゲームをつくる
・ゲーム開発コンテスト、ぷちコンに提出する。
・「没入型シミュレーション」と「創発的ゲームプレイ」のひみつ|ぱソんこ|note この、「科学演算」要素をいれたい
みっつめの科学演算ってのは、木を熱したら火が生じる~とか氷を放置してたら水になる~とかの組み合わせでなにか起こるかを予め決めといて、その上でゲームをつくっていくこと。それによってプレイヤーは「あー、これをこうしてこうなるんだったら、あれとコレを混ぜると...」みたいな学習というか実験っぽいおもしろさが生まれたりする...って解釈なんだけど合ってるかな
魔法使いになって大釜をグルグル回す体験がしたい。

こういうイメージ。

ラーメン屋シミュレーターとかみたいに一定時間内に薬を作って捌くゲーム
www.youtube.com
ステージはこんな感じ
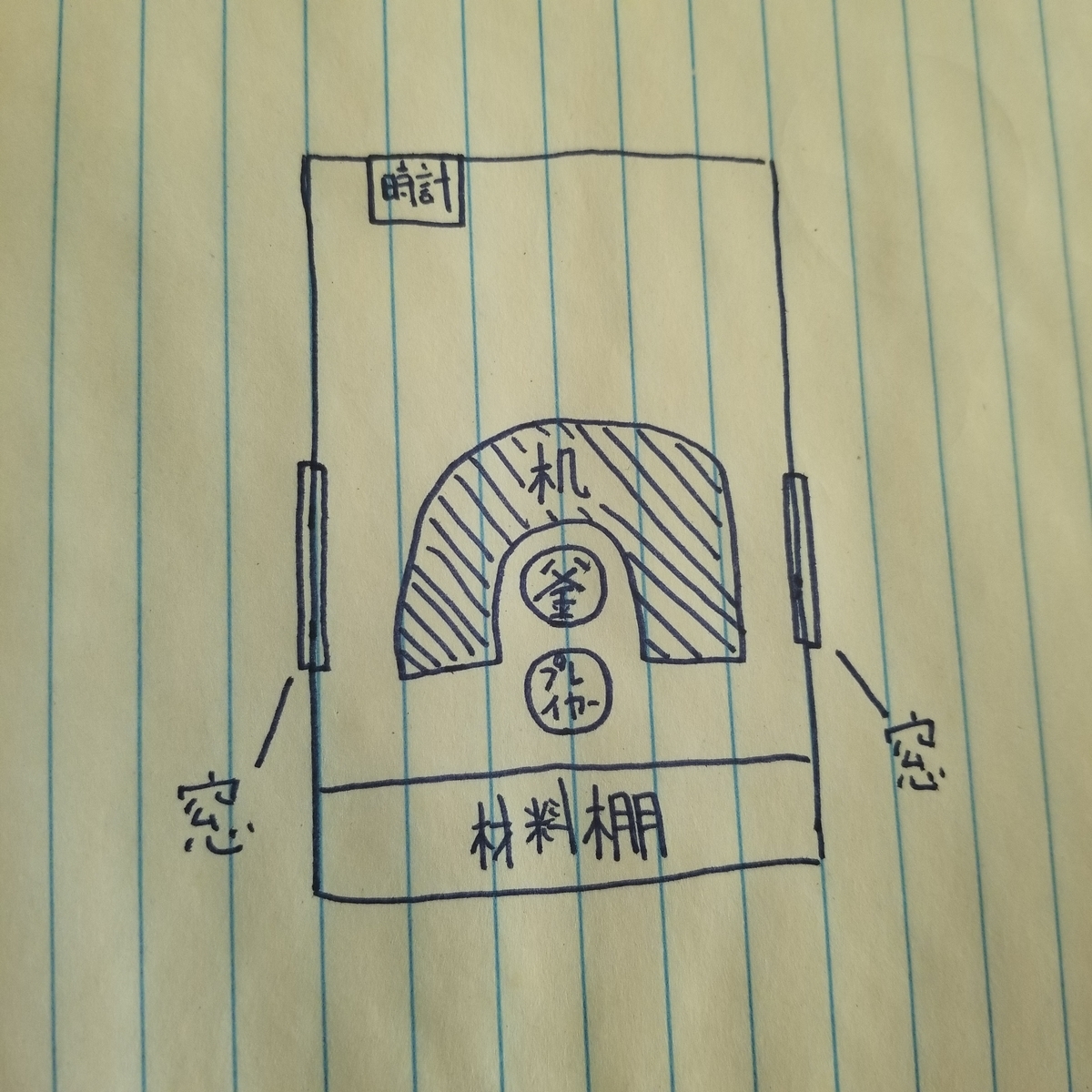
プレイヤーを一定の位置からあんまり動かしたくない。ビートセーバーみたいに棒立ちのまま腕だけブンブン振るだけで(実際にブンブン振る必要があるのかはわからないけど)遊べるのが理想かなって思ってる。小さいスペースで遊べるのと、動きまわるとすぐVR酔いしちゃう気がするから。もちろん、現実のプレイヤーを動かさないだけじゃなくてゲーム内のキャラも移動させたくない。酔うから

プレイ中の視界はこんな感じ。
ゲームの流れ
- ゲームスタート、朝が始まって終了までのカウントダウンも始まる
- 窓から薬作成の依頼を持った動物がやってきて「腹痛止めの薬をつくって」とか「風邪薬をくれ」とか言ってくる>

動物にもいくつかバリエーションあったら可愛い - 手元の本でレシピを確認する
- 材料の棚からレシピ通りに材料を選んで大釜で混ぜる
- 材料棚から空き瓶を拾って薬をそそぐ
- その時点でどういう薬か判定されて、ちゃんと混ぜられてるか 材料はちゃんとしてるかとかで点数がつく
- 依頼をもってきた動物に薬を渡して点数が合計点に入る(これ代金とかでいいのかも)
- 日暮れになって(時間が終了して)ゲームオーバー、一日に稼いだ金額がスコアになる
って感じ
UE4でVRゲームをつくりたくて
VRのゲーム、作りたいのでちょっとUnrealEngine4久々に起動して触ってる。
チュートリアルというかドキュメント的なのあんましなくて難航してるかも。
仮想現実のベスト プラクティス | Unreal Engine ドキュメント
↑これ読んだ。開発の方法ってよりかはVRコンテンツの手法というか気にすべきテクニックって感じだった。
- 爆発とかで衝撃を表現する時とか、画面を揺らさないで(VR酔いするから)
- プレーヤーの目線は普段のUE4での開発より少し下げといた方がいい
- 設置するモノはプレイヤーの目線や慎重を考えて実際のサイズと同じくらいにすると良い
- 階段よりエレベーターの方がいい
- 歩く時、画面を揺らさないで(酔うから)
- 色は彩度落とした方がいい
とか。今後役立ったらいいな。
でも今は人を吐かせてもいいから形をつくっていきたい。
Flutter触ってみた
なぜ
今年ずっと業務委託として関わらせてもらってる開発のプロジェクトがあるんですけど、今それを僕はReactを使ってWebアプリとして触ってるんですね。 でも内容がWebアプリに合ってる内容かと言われるとウーン...って感じなんです。PWAに対応するとか色々方法はあると思うんですけど(そもそも僕はPWAが好きじゃないんですけど)明らかにネイティブアプリとしてリリースした方が良さそう。
それで将来的にネイティブアプリに対応させる時とか自分が個人的にアプリ作りたいなーって時のためにネイティブアプリつくtれるようになっとこうってのが理由です。
なにを書くか
そんなに迷いませんでした。Flutterをかくことにしま。周りの人でFlutter良い!!みたいなこと言ってる人が多いのが理由です。
環境作ります
これ見ながらやりました。特に詰まるところもなく完成しました。前にUnrealEngineでARゲーム作った時にAndroidの実行環境作ってたのでそれもあって詰まらなかったのかもしれないです。(でも手順も少なかったから関係無いかな)
Flutter doctorってコマンドがあるんですね。Flutterの実行環境に足りないこととかをチェックリスト形式で返してくれる。
さすが天下のGoogle様だな! って感想です。
✗ Flutter extension not installed; install from https://marketplace.visualstudio.com/items?itemName=Dart-Code.flutter
ってエラーだけ、なんかVSCodeの拡張とか入れなきゃいけないみたいです。
できた
Flutter、こんなすぐ環境作れるんすね pic.twitter.com/WI2uYs0Ph9
— イイノテン (@iinoten) October 3, 2020
マジで楽ちんだった。なんか作るか~~~
CivitechChallengeCup[U-22]に参加してたって話
コレに参加していました。
8月最初くらいにツイッターで友達がおもしろそうなコンテストがあるっていうので一番のりしました。
出遅れてすいません、、僕はもうエントリー終わりましたがみんなは????? https://t.co/LLyEjiYPmW pic.twitter.com/v2M9f0zpBG
— イイノテン (@iinoten) July 20, 2020
なんかチームとか組んでないけどまあみんなコンテスト内のSlackで結成するみたいだし誰か空いてる人いるだろ~ってワークスペース入ったら知ってる人がほぼほぼ知り合い同士で組んでてぼっちで泣いてました。
「誰か~~班で空いてるとこないかな~ 飯野君はやくどこかのおともだちに声かけて班にいれてもらおうね~」って先生に言われて「あっあっ」ってなった小学生の自分を思いだしました。
ちなみに僕のチャンネル入っての一声はこちら

なんか運営からここ(自己紹介用のチャンネルがあった)で自己紹介してね~~みたいなこといわれたのに誰も発言しないから先人きったろうってはしゃいだらこうなった。
とりあえずどっかのチームに入るか~~~っておもったけど、入りたいチームもなかったので自分でつくってチームメンバーを募集した。
んでいろいろあって作ったのがこれ
ツイッターで拡散の勢いのあるツイートを取得して、信頼にたりる内容かどうかをチェックしてくれるbotを作った。初めてpython書いたので色々勉強になった。
チェックの方法としては、ツイートの文章内を分析したりして「人の目を引きやすい文章かどうか」とか「ソースとなるURLがあるかどうか」とか「URL先のことと合ってる内容の投稿かどうか」とかをみたりしてる。
良かったこと
チームリーダーやったのでチームでどうタスクを振ったらいいかとか俺はなにをすればいいのかとか色々知見が得られた。
あとpython、食わず嫌いだったけどわるくないなあって感想になった。数学的なことをするんだったらpythonってのもわかった気がする。便利なライブラリとか記事が多い。あとネットの記事が初学者向けなのがおおくて触りやすかった。
githubのページはこれ。がっつりコミットしてたので芝生がぼうぼうになってるのも満足感あっていいなあ
Pythonのmatplotlibとかで詳しく考える
経緯
俺もデータサイエンティストやってみます - 自由研究をします。
昨日、適当に散布図を作って遊んでたけど今回はちゃんと考えていく。
書いた
import matplotlib.pyplot as plt import json json_open = open('./analysed_netnewsdata.json', 'r') json_load = json.load(json_open) analysed_news_data_array = json_load['analysed_data'] # figureを生成する fig = plt.figure() # axをfigureに設定する ax = fig.add_subplot(1, 1, 1) # axesに散布図を設定する for index, analysed_result in enumerate(analysed_news_data_array): ax.scatter(x=len(analysed_result["text"]), y=analysed_result["documentSentiment"]["magnitude"], c='b', s=1) # 表示する plt.savefig("textlength_magnitude_graph.jpg")
前回書いたmatplotlibを使ったコードとほぼ同じ。点を配置する時にメソッドに渡す値を配列型のデータ群じゃなくてひとつひとつ値をforで回して渡すようにしてる。 今回見たかったのは解析した記事のテキストの量とGoogleNaturalLanguageの感情分析で出たmagnitudeの値の関係です。
出た散布図

(magnitudeが50とか出てるものとか極端に大きな記事は外している)
横軸が記事の文章の文字数 縦軸がmagnitudeの値
もっと直線的に表示されるかなって思ったけど割とバラけてて正直ビックリした。ちゃんと感情分析してスコアを出してるんだな (あたりまえだけど) もちろん大きい記事になるにつれmagnitudeの値が大きくなってる。(Googleのドキュメントにも「長いテキスト ブロックで値が高くなる傾向があります。」ってある)
読んでみる

なんかここに筋っぽいのが見える。赤くマーカーしたところ。要はこの横線の値である文章量の記事が多いっていえるんだと思う。この場合だったら600文字と800文字と1000文字。でもコレは文春オンラインにある記事がそうってだけで知りたいこととはなんの関係もない。
なんでかっていうと今回、最終的に知りたいのはTwitterでの投稿の際に感情がそんなもんだったらバズりに繋るか(人の目を引きやすいか)なので140文字の制限があるTwitterで何百文字もの記事と相関をつけようったって無理な話。今回は大衆誌の記事文をモデルに進めてるけど、もしそれらが「200文字だったらmagnitudeが10なのが良いかんじで、500文字だったら30くらいなのがちょべりぐだよ」みたいな結果を出しててもそれをそのまま140文字に当てはめてもなあ...ってかんじ(200文字でmagnitudeが10なのが良いんだったらTwitterなら8くらいがいいのかなあとかも違う気がするし(だってモデルの記事達とTwitterの投稿文の量の差異があまりにもありすぎる。これがTwitterの文字数が平均的に300とかだったら今出てる結果でよかったと思う))。だからさっき出したグラフで得れた有効そうな情報は割とちゃんとバラけてることから「ちゃんと感情の大きさを見てくれてるっぽい」ってことと「文字量と感情のデカさはやっぱり関係あるっぽい」ってこと。
んで
じゃあこのクソデカ記事達とTwitterに投稿されてる文章をどうやってひもづけるか、なんだけど 「記事の中身を文で分けてその文の数との関係性を見てみる」でやってみる。
書いた。
tweet-test-bot/analyse_newsdata_sepalate.py at master · iinoten/tweet-test-bot · GitHub
もうプログラムのコードそのまま記述するのやめよかな。めんどくさ
内容としては前回書いた分析の結果をjsonの配列に収める際に文毎の分析結果も配列化しておしこむようにしただけのもの。一部が二次元配列みたいになってるからめちゃくちゃネストされて合計4万3千行とかのファイルになっちゃってる。
jsonファイルはコレ↓
んで
さっきのとこまでを書いたのが2時間くらい前で、行ごとにいろいろ出すコードを書いてた。でも今ふと思ったけど文で分けてどうするつもりだったんだろう。文の数と記事全体の長さってそれこそ比例して多くなっていくしTwitterの短文にはどうしてもあてはまらない。どうしよう。
とりあえず書いちゃったから文ごとのscoreを散布図におこそうとしてみる。
で
こうなった
43000行のデータファイルをグラフ化しようとしてファンがブンブン唸り出してからはや5分。 pic.twitter.com/PZOb2I4i4E
— イイノテン (@iinoten) September 23, 2020
ウーン

10分くらいで出力された。「そこまで大きく感情を表わす文はないのんな~」「割とポジティブな文もネガティブな文も平等にあるのんな~」くらいしかわからない。最後の気付きは重要かも。そこからヒントを得て、明日はひとつの記事内から感情の変動をみるってことをしてみよっかな
夜中に作業は効率よくないかも